
XPathとは
XPath(XML Path Language)とは、XML形式の文書から、特定の部分を指定して抽出するための簡潔な構文(言語)です。HTML形式の文書にも対応します。
CSSではセレクタを使ってHTML文書内の特定の部分を抽出しますが、XPathはより簡潔かつ柔軟に指定ができるとされています。以下の例はbody以下のリンク要素(hogeクラス)を取り出す書き方です。
CSSセレクタ
html > body a.hogeXPath
/html/body//a[@class="hoge"]XPathを試してみる
上記のとおり、XPathはHTMLのパースに使えます。なのでHTMLに対してXPathでデータを抽出するのがお試しとしては簡単でしょう。
Google Chrome で XPath を書いてみる
Google Chrome の開発者ツールには、XPathによる検索機能があります。これを使えば、面倒な環境構築などは不要で、いきなり表示しているページから、ほしい要素の検索を試すことができます。まずは、上で紹介したXPathのサンプルを使って次のリンクを取得してみます。
↓これを探す
hoge
Chromeでこのページを表示し、右クリックメニューの[検証]から開発者ツールを表示します。表示されているElementタブのhtmlから “Ctrl + F” で検索欄を表示します。上のXPathを入力すると、得られる要素が選択されるはずです。
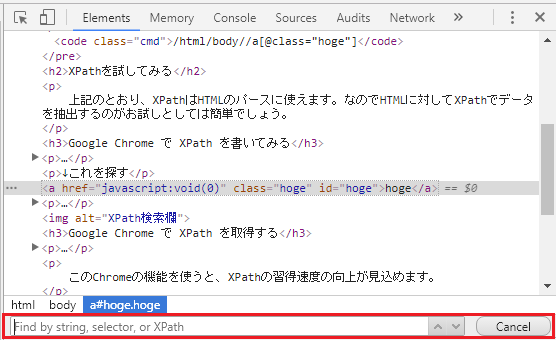
Google Chrome で XPath を取得する
画面上の要素を取得するためのXPathを逆引きすることも可能です。同じく開発者ツールのElementsタブのhtmlで、要素を右クリックします。メニューの[Copy] → [XPath Copy] でその要素を取得するためのXPathがクリップボードにコピーされます。もちろん一例ですが、参考にするには十分です。
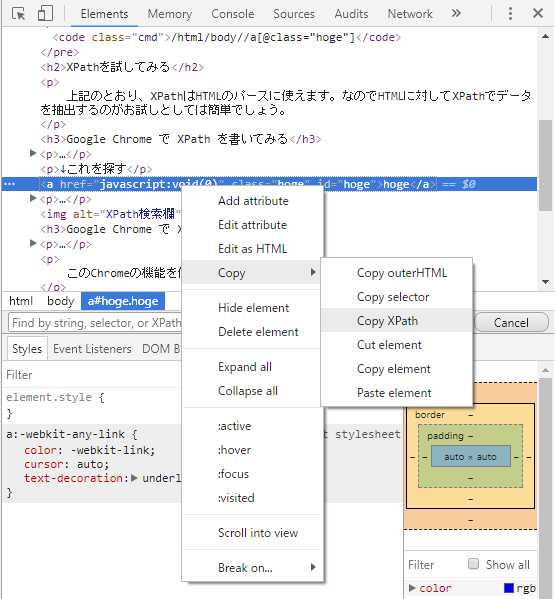
このChromeの機能を使うと、XPathの習得速度の向上が見込めます。
XPathの構文
CSSセレクタに様々な指定方法があるのと同じように、XPathにも様々な構文が存在します。まずは、基本的な事柄を、さらに代表的な構文をまとめました。
XPathとノード
XPathが扱う文書は、以下の種類に分類されます。これらのノードをXPathで取得することができます。
- ルートノード
- 要素ノード
- 属性ノード
- テキストノード
- コメントノード
- 処理命令ノード
- 名前空間ノード
ロケーションパス(省略構文)
XPathの最も一般的な書き方で、基準となるノードから別のノードを指定できます。基本はスラッシュ “/” で区切りながら階層を記述します。URLと似ています。
例えば、html(ルート)要素の子要素bodyの子要素aをは、次のように示します。
/html/body/aスラッシュで区切られた部分をロケーションステップといい、各種構文を使って記述していきます。正式構文のほうは冗長ですが、多くのオプションを記述できるようです。以下にまとめたのは省略構文での記述サンプルです。
- 絶対パス
-
/html/bodyスラッシュ始まりの記述はルートからの絶対パスを意味します。この例の場合、ルート要素のhtmlの子要素に当たるbody要素を指定しています。
- 相対パス
-
html/bodyスラッシュ始まりではないので、コンテキストノードからの相対パスを意味します。
- 全要素
-
div/*アスタリスク(*)は全要素を意味します。この例だと、div要素の全子要素を指定しています。
- ドキュメント内のすべての要素
-
//* - 子要素
-
div/pスラッシュは子要素を意味します。この例ではdiv要素の子要素に当たるp要素を指定しています。
- 子孫要素
-
div//*スラッシュ2つで子孫要素を意味します。この例ではdiv要素の子孫要素すべてを指定しています。
- 親要素
-
a/..ピリオド2つで親要素を意味します。この例ではa要素の親要素を指定しています。
- idで要素を指定
-
id("hoge")id関数を使って、idで要素を指定できます。
- 属性を取得
-
//a/@hrefアットマークで属性ノードを取得できます。この例ではaリンクに設定されているhref属性を取得します。
- 属性で要素を指定
-
//*[@href="./index.html"]アットマークで属性を指定できます。この例では、すべての要素のうちhref属性が./index.htmlの要素のみを指定しています。属性そのものを持つかどうかの条件は次のようにします。
//input[@disabled] - 子要素に特定の要素が含まれるものを指定
-
//div[a]a要素を子要素に持つdiv要素を指定するには、角括弧を使って記述します。
- N番目の要素を指定
-
//table//tr[3]複数に合致する場合に、N番目の要素を指定することができます。この例では、tableの行から3行目を取得しています。first()関数もしくはlast()関数を使い、先頭もしくは最終要素を取得できます。
//table//tr[last()] - 演算子や関数
-
XPathでは様々な演算子や関数で複雑な条件を指定できます。
以下に使えるものの一覧を示します。Wikipediaからの引用です。
演算子 備考 |2つのノード集合の和集合のノード集合を返す。 and論理積 or論理和 +足し算 -引き算 *掛け算 divIEEE 754に基づく割り算 mod剰余 =等価 !=等価でない <小なり <=小なりまたは等価 >=大なりまたは等価 >大なり 関数名 備考 concat与えられた文字列を連結した文字列を返す。 substring指定された範囲の部分文字列を返す。 contains指定された文字列が部分文字列として含まれる場合に真値を返し、それ以外の場合に偽値を返す。 starts-with指定された文字列が先頭の部分文字列である場合に真値を返し、それ以外の場合に偽値を返す。 ends-with指定された文字列が末尾の部分文字列である場合に真値を返し、それ以外の場合に偽値を返す。 substring-before指定された文字列よりも前にある部分文字列を返す。 substring-after指定された文字列よりも後ろにある部分文字列を返す。 translatenormalize-spacestring-length文字列の長さを返す。 sum総和を返す round四捨五入関数 floor床関数 ceiling天井関数


![[Javascript] Webページ印刷時のTips](https://webbibouroku.com/wp-content/uploads/eye_html.png)