![05 構文解析器と抽象構文木を作る [オリジナル言語インタプリタを作る]](https://webbibouroku.com/wp-content/uploads/eye_gorilla.png)
構文解析器(パーサー)
構文解析器(パーサー)の役割は、入力データから何らかのデータ構造を構築することです。データ構造はたいてい構文木や抽象構文木などの階層的な構造で定義され、入力に対して構造化された表現を与えます。また、その過程で入力が正しい構文かどうかをチェックします。
多くの場合構文解析器は字句解析器の後におかれ、字句解析器から得られたトークン列を入力として受け取ります。
今回作成する構文解析器は抽象構文木を作成します。トークン列を受け取り、1つの木構造のデータに変換します。
抽象的で分かりにくいので具体的に実装しながら見ていきます。
式(Expression) と 文(Statement)
まず実装前に式と文について用語を整理しておきます。
式とは 値を生成するもの であり、文とは 値を生成しないもの です。厳密には何が式で何が文かは各種プログラミング言語によって異なるようですが、今回実装しているプログラミング言語において、式と文の違いは値を生成するか否かです。
また、ある構文が式か文かも実装するプログラミング言語によって異なります。例えば if という構文は多くのプログラミング言語で実装されており、もちろんC#でも実装されています。C#のifは値を生成しないので、ここでの定義からすると文に該当します。一方、ifが値を生成する if式 のプログラミング言語も存在しています。
実装中の言語 Gorilla はほとんどが式となります。
抽象構文木(Abstract Syntax Tree)
抽象構文木(Abstract Syntax Tree) は以下、その頭文字をとって AST と呼びます。プロジェクトにASTディレクトリを作成し、以下に各種ノードに対応するクラス等を定義していきます。
ASTの各ノードは、式もしくは文のいずれかからなります。したがって以下の3つのインターフェースを定義します。
Ast/INode.cs
namespace Gorilla.Ast
{
public interface INode
{
string TokenLiteral();
}
}
Ast/IStatement.cs
namespace Gorilla.Ast
{
public interface IStatement: INode
{
}
}
Ast/IExpression.cs
namespace Gorilla.Ast
{
public interface IExpression: INode
{
}
}
ASTのすべてのノードは、INode を実装します。また、すべてのノードは、式(IExpression)か文(IStatement)のいずれかです。
したがって、すべてのノードは TokenLiteral() を定義しなければなりません。これはこのノードに紐づけられるトークンを返すメソッドです。これはデバッグ用途でのみ利用するものです。
ルートノード
AST は木構造なので、ルートとなるノードが必要です。Root という名前で定義します。ルートノードのみ式でも文でもありません。
Ast/Root.cs
using System.Collections.Generic;
using System.Linq;
namespace Gorilla.Ast
{
public class Root : INode
{
public List<IStatement> Statements { get; set; }
public string TokenLiteral()
{
return this.Statements.FirstOrDefault()?.TokenLiteral() ?? "";
}
}
}
ルートノードは、実行するプログラムを子要素として保持します。すべての有効なコード文の集まりです。
基本的に、let文(let a = 1+1;)みたいに文の集まりから Gorilla のプログラムは構成されることになります。式はlet文の右辺のような値が必要になる箇所に登場します。
したがってプログラムのトップレベルには文が来ることになります。
let 文
では最初の1歩として、let文 の構文解析を行います。まずはlet文の構文について考えてみます。
let文は、与えられた変数名を値に束縛します。aという名前に値1を束縛するコードは以下の通りです。
let a = 1;
まず、letキーワードがあり、そのあとに変数の名前が必要です。さらに続けて等号(=)があり、その右辺に変数の名前が束縛される値を生成する式(Expression)が必要です。
右辺の値はリテラル値だけでは不十分です。関数リテラルもあり得ますし、関数の実行結果も受け取れる必要があり、つまりあらゆる式が有効であるべきです。
let a = 1;
let b = a + 1;
let c = b;
let d = fn(x, y) {
return x + y;
};
let f = add(1, 2);
上記のようなコードが考えられます。右辺を式(Expression)としてひとまず置いておくと、let文のプログラムは以下のように定義されます。
let <identifier> = <expression>;
つまり、文(Statement)が来るべき箇所で let が来たらその直後は、識別子(Identifier) 出なければならず、その直後は等号(=)、その次に式です。識別子と等号はすでに字句解析で1つのトークンになっているのでわかりやすいですね。
なんとなく構文解析の処理を書ける気がしてきました。次はこのlet文をどのような値を持ったノードとして定義すればよいかを考えます。左辺の変数名と右辺の式を持つ必要があります。また、letトークンも持ちます。
Ast/Statements/LetStatement.cs
using Gorilla.Ast.Expressions;
using Gorilla.Lexing;
namespace Gorilla.Ast.Statements
{
public class LetStatement : IStatement
{
public Token Token { get; set; }
public Identifier Name { get; set; }
public IExpression Value { get; set; }
public string TokenLiteral() => this.Token.Literal;
}
}
文なので IStatement を実装します。プロパティで 右辺の識別子 Name、左辺の式 Value を持ちます。
Token は Letトークンを指します。TokenLiteral() がこのトークンのリテラル(つまり “let”)を返します。
左辺の識別子については Identifier 型を別途作成します。
Ast/Expressions/Identifier.cs
using Gorilla.Lexing;
namespace Gorilla.Ast.Expressions
{
public class Identifier : IExpression
{
public Token Token { get; set; }
public string Value { get; set; }
public Identifier(Token token, string value)
{
this.Token = token;
this.Value = value;
}
public string TokenLiteral() => this.Token.Literal;
}
}
Identifier 型は式です。値を生成します。左辺に来る場合は値を生成するのは変ですが、識別子は右辺に来る場合もあります。したがって値を生成する式として定義しなければ都合が悪いのです。
プロパティはTokenと、変数名を指す Value です。
ここまでの説明を図にすると以下のようになります。
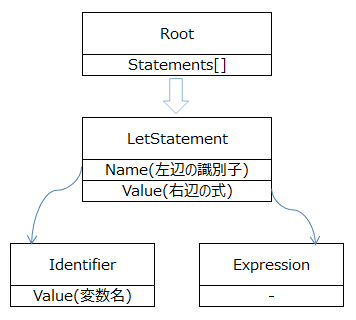
Paserの実装第1歩
では、ようやく必要なパーツの定義が済んだので、上の画像のようなデータを作成してみましょう。まずは Parser クラスを定義します。Parser はトークン列を入力として受け取り、抽象構文木を生成します。
とはいえトークン列すべてを受け渡すのではなく、必要に応じて都度取り出して利用するようにします。そのために字句解析器のインスタンスをコンストラクタで渡します。
using Gorilla.Lexing;
namespace Gorilla.Parsing
{
public class Parser
{
public Token CurrentToken { get; set; }
public Token NextToken { get; set; }
public Lexer Lexer { get; }
public Parser(Lexer lexer)
{
this.Lexer = lexer;
// 2つ分のトークンを読み込んでセットしておく
this.CurrentToken = this.Lexer.NextToken();
this.NextToken = this.Lexer.NextToken();
}
private void ReadToken()
{
this.CurrentToken = this.NextToken;
this.NextToken = this.Lexer.NextToken();
}
public Root ParseRoot()
{
return null;
}
}
}
字句解析器と同じような実装で、現在のトークンと先読みしたトークンを状態として保持します。
ReadToken() はトークンを読み進めるためのヘルパーメソッドです。
ParseRoot() が構文解析を行うためのメソッドです。ここからすべてが始まります。字句解析器からトークンを順次取り出し、抽象構文木を生成します。ひとまずは null を返しています。
ここから先の実装を進めるために、テストを書きましょう。そうしなければいけないルールなのです。
ParserTest.cs
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Gorilla.Lexing;
using Gorilla.Parsing;
using Gorilla.Ast.Statements;
using Gorilla.Ast;
namespace UnitTestProject
{
[TestClass]
public class ParserTest
{
[TestMethod]
public void TestLetStatement1()
{
var input = @"let x = 5;
let y = 10;
let xyz = 838383;";
var lexer = new Lexer(input);
var parser = new Parser(lexer);
var root = parser.ParseProgram();
Assert.AreEqual(
root.Statements.Count, 3,
"Root.Statementsの数が間違っています。"
);
var tests = new string[] { "x", "y", "xyz" };
for (int i = 0; i < tests.Length; i++)
{
var name = tests[i];
var statement = root.Statements[i];
this._TestLetStatement(statement, name);
}
}
private void _TestLetStatement(IStatement statement, string name)
{
Assert.AreEqual(
statement.TokenLiteral(), "let",
"TokenLiteral が let ではありません。"
);
var letStatement = statement as LetStatement;
if (letStatement == null)
{
Assert.Fail("statement が LetStatement ではありません。");
}
Assert.AreEqual(
letStatement.Name.Value, name,
$"識別子が間違っています。"
);
Assert.AreEqual(
letStatement.Name.TokenLiteral(), name,
$"識別子のリテラルが間違っています。"
);
}
}
}
テストはソースコードを与え、字句解析するところから始めています。字句解析器をモックにすることでテストの独立性が高まりますが、トークン列よりもソースコードを入力として与える方が読みやすいので妥協しています。見やすいですが、字句解析器のバグの影響を受けるので注意が必要です。
気になる人はモック化してみるといいでしょう。
テストはひとまずlet式について、letトークンと左辺の識別子についてのみテストしています。右辺の式のパースについては、あとでテストします。
当然このテストは失敗です。ParseRoot() が何もせず Statements が空のためです。これを通すために実装をしていきます。
テスト名: TestLetStatement1
テストの完全名: UnitTestProject.ParserTest.TestLetStatement1
テスト ソース: E:\work\cs\Gorilla\UnitTestProject\ParserTest.cs : 行 13
テスト成果: 失敗
テスト継続時間: 0:00:00.0400871
結果 のスタック トレース: at UnitTestProject.ParserTest.TestLetStatement1() in E:\work\cs\Gorilla\UnitTestProject\ParserTest.cs:line 24
結果 のメッセージ: Assert.AreEqual failed. Expected:<0>. Actual:<3>. Root.Statementsの数が間違っています。
ParseRoot()
ParseRoot() はルートノードを生成するのが役割です。なのでまずはRootクラスを生成します。そして、ルートレベルのには文しか来れないので、文をパースしなければなりません。すべてのトークンがパースされるまで文のパースを続けます。なので文をパースするメソッドを定義します。
ParseStatement() は文をパースするメソッドです。ひとまず null を返す形で実装してみます。
public class Parser
{
// ..
public Root ParseProgram()
{
var root = new Root();
root.Statements = new List<IStatement>();
while (this.CurrentToken.Type != TokenType.EOF)
{
var statement = this.ParseStatement();
if (statement != null)
{
root.Statements.Add(statement);
}
this.ReadToken();
}
return root;
}
public IStatement ParseStatement()
{
return null;
}
}
ParseProgram() は、やっていることは単純でループしながら式をパースして式のASTを生成します。生成された式をルートに追加します。パース後にはトークンを読み進めるのをお忘れなく。
次に ParseStatement() を実装します。ここではすべての式のパターンを網羅してパースしなければなりません。ということで先にASTを定義したlet文のみをパースできるようにします。
ということで LetStatement を返す ParserLetStatement() を追加します。もちろんその中で、Identifier と Expression をパースしなければなりません。一気に実装してしまいます。
public class Parser
{
// ..
public IStatement ParseStatement()
{
switch (this.CurrentToken.Type)
{
case TokenType.LET:
return this.ParseLetStatement();
default:
return null;
}
}
public LetStatement ParseLetStatement()
{
var statement = new LetStatement();
statement.Token = this.CurrentToken;
if (!this.ExpectPeek(TokenType.IDENT)) return null;
// 識別子(let文の左辺)
statement.Name = new Identifier(this.CurrentToken, this.CurrentToken.Literal);
// 等号 =
if (!this.ExpectPeek(TokenType.ASSIGN)) return null;
// 式(let文の右辺)
// TODO: 後で実装。
while (this.CurrentToken.Type != TokenType.SEMICOLON)
{
// セミコロンが見つかるまで
this.ReadToken();
}
return statement;
}
private bool ExpectPeek(TokenType type)
{
// 次のトークンが期待するものであれば読み飛ばす
if (this.NextToken.Type == type)
{
this.ReadToken();
return true;
}
return false;
}
}
ParseStatement() は現在のトークンが let トークンであれば ParseLetStatement() を呼び出します。
ParseLetStatement() がここで重要なメソッドです。この処理が呼ばれる時点でトークンはletになっています。これが LetStatement オブジェクトの Token プロパティに設定されます。
続けて左辺、等号、右辺とトークンを読み進めます。読み取ったトークンから各オブジェクトを生成して、let文のASTが完成します。特に難しい処理ではありませんのでコードを読めばわかります。
式のパースについてはまだ実装がないので、とりあえず式の終了のセミコロンまで読み飛ばして対応しています。ここは後で実装します。
ExpectPeek() は次のトークンを先読みし、期待するトークンかどうかを判定します。期待するトークンであれば次のトークンに読み進めます。そうでなければ何もせず判定結果のみを返します。これは構文解析器によくある処理らしいです。
どうでしょうか。少し複雑になってきました。しかしこれでlet文の左辺については正しくパースできるようになりました。つまりテストが通ります。グリーンです!!
テスト名: TestLetStatement1
テストの完全名: UnitTestProject.ParserTest.TestLetStatement1
テスト ソース: E:\work\cs\Gorilla\UnitTestProject\ParserTest.cs : 行 14
テスト成果: 成功
テスト継続時間: 0:00:00.0056246
テストがグリーンになったところでここまでにします。
まとめ
ここまでのソースです。
mntm0/Gorilla at ca7aa80fab3e990dec51413adbaf31368dd2d4e3
ひとまずlet文の構文解析ができるようになりました。左辺のみですが。やることは、トークン列を見ながら必要なASTを生成することのみです。そのためにトークンを先読みして云々という点は、基本的には字句解析と同じ感じですね。
次回は、Errorを出力できるようにします。今のところ予期せぬトークンがあっても Null を返すだけで、そして Null は パース時に無視されるのでデバッグが困難です。これを何とかして、できるところまで進める感じですね。
以上。
