世界には同じような国旗が存在している
世界には多くの国があり、いろいろな国旗がります。ご存知の通り国旗のデザインが非常に似通った国があります。例えば次の例、2つの似た国旗ですがどの国のものかわかりますか?


片方はスーダン、もう片方はクェートです。
ほかにも似たような国旗の国はたくさんあります。一番わかりやすいのだとユニオンジャックが含まれる国旗でしょうか。
国旗を機械学習の力でクラスタリングする
似ている国旗をいろいろ集めてみたくなったので、機械学習の力をかりて国旗の画像データをクラスタリングしてみます。
求めたいのはなんとなく似ている国旗のグループなので、教師なし学習 になります。
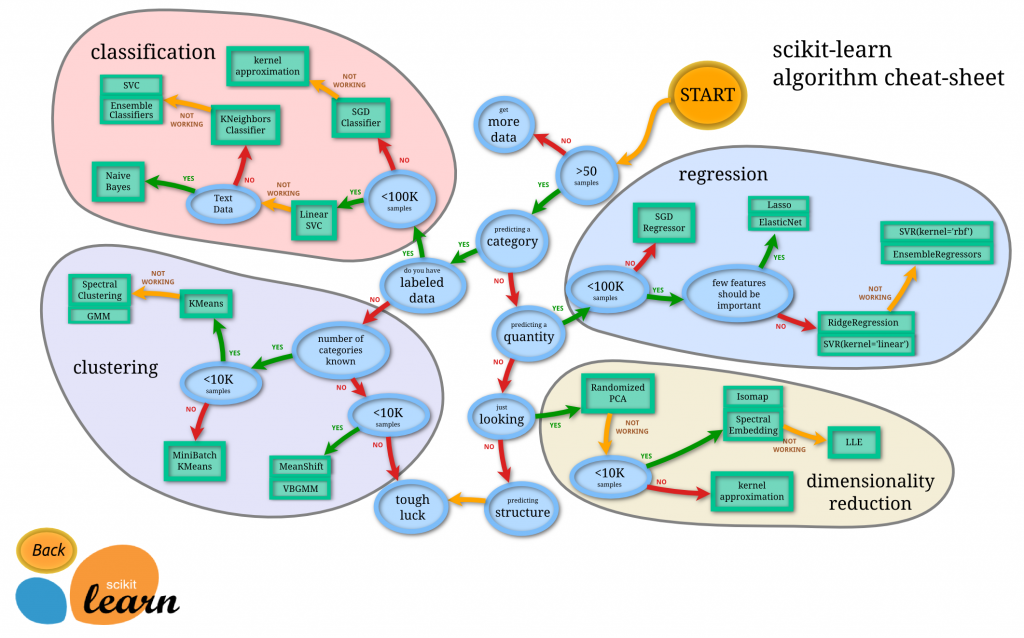
scikit-learn と k平均法
scikit-learn というライブラリを使うとお手軽にできるのでこれを利用していきます。
データをクラスタリングするためのアルゴリズムはいくつかあるのですが今回は、k平均法 というアルゴリズムを使用したいと思います。
このアルゴリズムは以下のチートシートから選びました。
国旗画像を集める
まずはともあれデータを収集しないといけません。適当なページ(国旗の一覧 – Wikipedia)から国旗画像をダウンロードするなりして用意しておきます。私はpng形式の画像を用意しました。
画像サイズはまちまちです。そもそも国旗には決められたサイズはなく、国旗によって縦横比も様々です。あとで無理やり整形するのでデータはそのままでOKです。
画像フォルダ構成
├─── flag_origin/ -- 国旗画像pngファイルを保存しておく
├─── flag_convert/ -- 同一サイズに変換した国旗画像(jpg)を保存
└─── flag_group/ -- 学習結果によってグループ分けされた画像を保存
├─── 0/
├─── 1/
├─── ...
└─── 14/
上記のようなフォルダ構成を作っておきます。最終的に15の似たものグループに分け、flag_group 以下のフォルダに元画像をコピーします。
用意した国旗画像は flag_origin 以下に全部コピーしておきます。
コード
import os
import shutil
import numpy as np
from PIL import Image
from skimage import data
from sklearn.cluster import KMeans
# 1. 国旗画像のサイズをそろえて保存する
# ./flag_origin 以下に国旗画像
# ./flag_convert 以下に200*100のサイズに変換したjpgを保存
for path in os.listdir('./flag_origin'):
img = Image.open(f'./flag_origin/{path}')
img = img.convert('RGB')
img_resize = img.resize((200, 100))
img_resize.save(f'./flag_convert/{path}.jpg')
# 2. 3次元配列の画像データを2次元配列のデータに変換
feature = np.array([data.imread(f'./flag_convert/{path}') for path in os.listdir('./flag_convert')])
feature = feature.reshape(len(feature), -1).astype(np.float64)
# 3. 学習(15種類のグループにクラスタリングする)
model = KMeans(n_clusters=15).fit(feature)
# 4. 学習結果のラベル
labels = model.labels_
# 5. 学習結果(クラスタリング結果の表示 + ラベルごとにフォルダ分け)
# ./flag_group 以下に画像を分けて保存する
for label, path in zip(labels, os.listdir('./flag_convert')):
os.makedirs(f"./flag_group/{label}", exist_ok=True)
shutil.copyfile(f"./flag_origin/{path.replace('.jpg', '')}", f"./flag_group/{label}/{path.replace('.jpg', '')}")
print(label, path)
順にコードを解説していきます。
1. 国旗画像のサイズをそろえて保存する
集めた画像はサイズがバラバラでそのままでは使えないので、同一サイズの画像データに変換します。サイズを200*100にしているのは大体2:1くらいの縦横比の国旗が多いからです。大きなサイズの画像だと処理に時間がかかったので、とりあえずこれくらいにしています。
元画像はpngファイルだったのですが、データの次元数がうまくあわなかったので、一律jpgファイルに変換しています。
変換したjpgファイルを ./flag_convert 以下に保存して、これをクラスタリングします。
for path in os.listdir('./flag_origin'):
img = Image.open(f'./flag_origin/{path}')
img = img.convert('RGB')
img_resize = img.resize((200, 100))
img_resize.save(f'./flag_convert/{path}.jpg')
実際に変換された画像を見ればわかりますが、引き伸ばされたり縮小されたりで、縦横比が潰れていたりするものが多いです。いい感じに処理する方法もわからないので、これで妥協してますが、いい方法を知っている人がいれば教えてください。
2. 3次元配列の画像データを2次元配列のデータに変換
画像データを読み込むと3次元配列((100, 200, 3))のデータになります。これを reshape で2次元((100, 600))に変換します。
feature = np.array([data.imread(f'./flag_convert/{path}') for path in os.listdir('./flag_convert')])
feature = feature.reshape(len(feature), -1).astype(np.float64)
ここまででデータの準備は完了です。あとはライブラリで用意されている関数に流し込むだけです。
3. 学習(15種類のグループにクラスタリングする)
今回使うアルゴリズム「k平均法」は、あらかじめいくつのデータにクラスタリングするか決めて置かなければなりません。今回は適当に15にしてます。
n_clusters で指定しているのがそれです。
model = KMeans(n_clusters=15).fit(feature)
4. 学習結果のラベル
学習が完了したら結果ラベルを受け取ります。ラベルは整数の 0~14 で割り振られています。同じラベルの画像は類似度が高いという判定です。
labels = model.labels_
labels の中身はただの配列です。
5. 学習結果(クラスタリング結果の表示 + ラベルごとにフォルダ分け)
最後に得られたラベルをもとに、似ている画像をフォルダにコピーしてまとめます。
for label, path in zip(labels, os.listdir('./flag_convert')):
os.makedirs(f"./flag_group/{label}", exist_ok=True)
shutil.copyfile(f"./flag_origin/{path.replace('.jpg', '')}", f"./flag_group/{label}/{path.replace('.jpg', '')}")
print(label, path)
似ている国旗の判定結果
15グループの国旗は次のようになりました。
ユニオンジャック系

イギリスの国旗ユニオンジャックを含む国旗たちはきれいに別れてました。代表的な国としては、オーストラリアやニュージーランドが挙げられます。
フランス国旗(フランス領南方・南極地域)が混じっていますが、まあ確かに似ていると言えます。
ただし、ユニオンジャック本体は別のグループに分かれる結果となりました。
トリコロール的な

三色縦割りの国旗(イタリア・フランスなど)のグループです。これもわかりやすいですね。白色が入っているとこのグループになるようです。
トリコロールではない判定

これも三色縦割りですが、上のグループとは別判定でした。
赤系

これは赤いので同じグループでしょうか。
あんまり似ていないアメリカ国旗群

アメリカ国旗が含まれるグループです。ユニオンジャックもここにありました。
アメリカ国旗に似たものが含まれていますが、全体の印象としてはバラバラな感じです。
青・緑系のややこしい模様

国旗はあまり複雑な意匠が含まれていないことが多いので、このグループも確かにそういう意味では似ているといえそうです。
全体的に青・緑系でまとまっています。
ただ、ほとんどどの国の国旗なのかわかりません。
薄味系

日本の国旗を含むグループです。全体的に白の割合が多いようです。
緑・白・青

ファミマっぽい国旗は、シエラレオネです。
3段の国旗

これは縦に3段になっている国旗のグループです。
赤黄色?

色味的には近いものがありそうですが、あまり特徴的なグループではない気がします。今回ではこのグループが一番ぼんやりとしたグループでしょうか。
なんとなく似ているが微妙

なんとなく似ているような気もするグループです。
白を含んだ横縞

白プラス横縞模様の国旗たちです。
細いストライプ

ほかのグループに比べて細い横縞が入っているといえる気がします。
ギザギザ

ギザギザや角ばった箇所がある、と言えなくもないグループでしょうか。
緑系雑多

今回一番数の多くなったグループでした。緑系のいろいろですね。
雑感
思いつきでやってみた割に、なんとなく形になっていてよかったです。もっとパラメータや入力データを調整すれば、いい感じになるのかもしれません。
scikit-learn はお手軽に機械学習を試せますし、また何か思いついたら触ってみたいと思います。
参考URL
- scikit-imageで画像処理 – Qiita
- scikit-learn: machine learning in Python — scikit-learn 0.19.1 documentation
以上。

![[Python] for, while で else句を使ってフラグ管理する](https://webbibouroku.com/wp-content/uploads/eye_python.png)